1. What is a Neural Network?
At its core, a Neural Network (NN) is a computing system inspired by the structure of the human brain. Think of it as a web of connected “nodes” (like digital neurons). These connections pass signals to each other, and each connection is modified by a “weight,” which is just a number.
The network’s primary goal is to learn to recognize complex patterns in data (like images, text, or sounds).
2. The Core Components & Layers
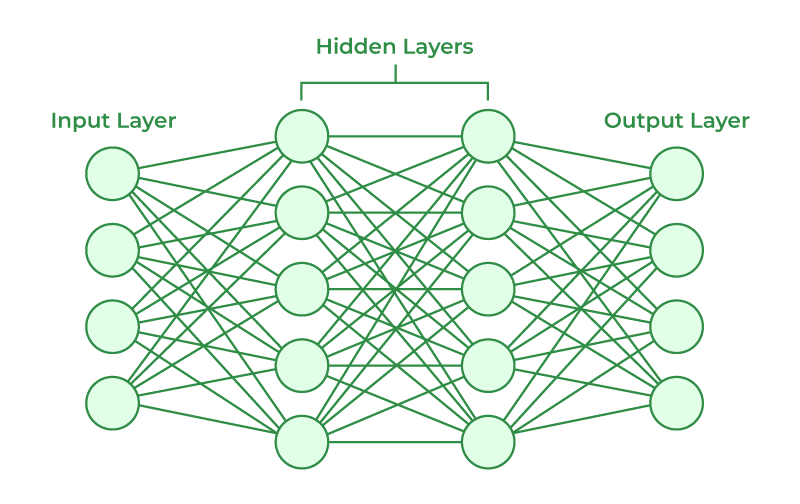
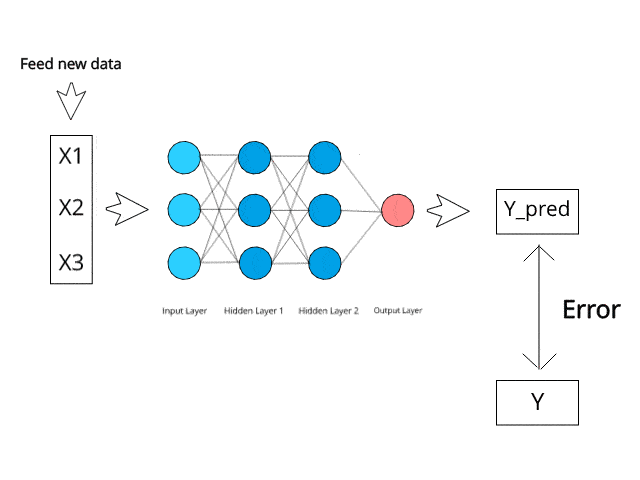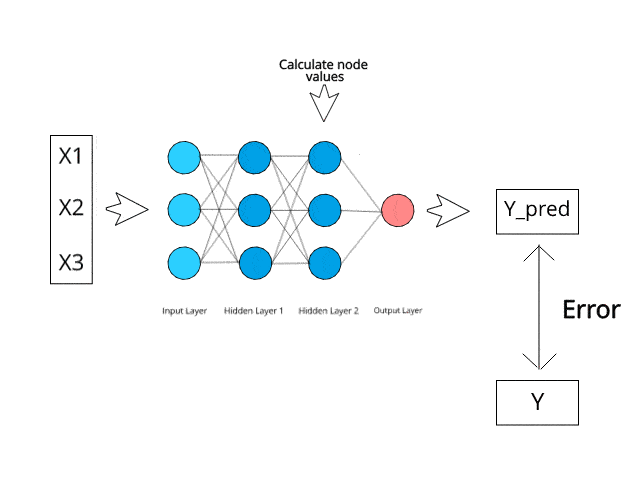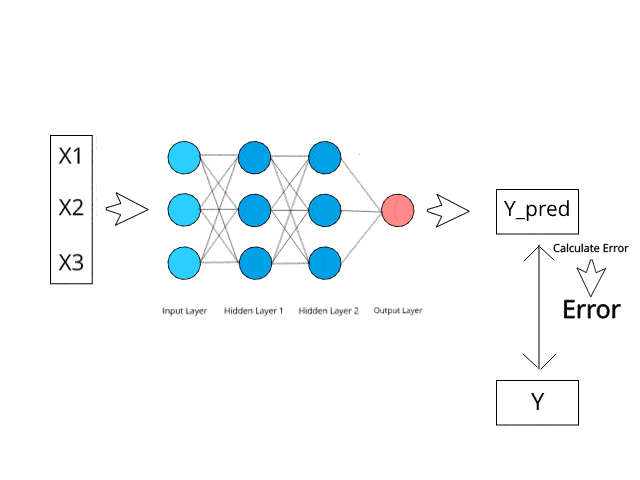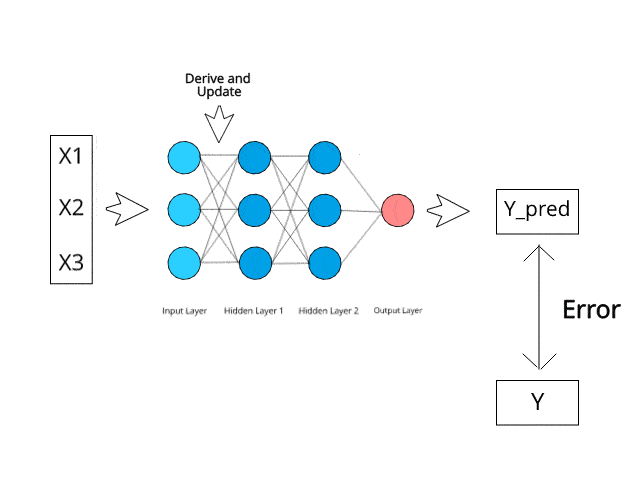
A neural network is typically organized into three types of layers, which contain the main functional components.
1. Input Layer (1st layer)
What it is: This is the very first layer of the network.
Its Job: It receives the raw data you want to process. This data is called the input.
Example: If you’re analyzing a picture, the input layer would receive the value of every single pixel.
2. Hidden Layer(s) (Intermediate Layers/2nd layer)
What it is: These are the intermediate layers between the input and the output. A network can have one hidden layer (making it simple) or many hidden layers (making it “deep” — as in “Deep Learning”).
Its Job: This is where all the main “processing” happens. The network combines the inputs and uses what it has learned to find patterns.
Key Concepts Inside:
Weights: Every connection between nodes in the network has a weight. A weight is a number that determines how important that connection’s signal is. A high weight means the signal is strong; a low weight means it’s weak. The network’s “knowledge” is stored in these weights.
Activation Function: Inside each node is a simple mathematical function. It decides whether the node should “fire” (pass on a signal) and what the strength of that signal should be. This helps the network learn complex, non-linear patterns.
3. Output Layer (3rd Layer)
What it is: This is the final layer of the network.
Its Job: It produces the final result or prediction.
Example: If you are building a network to recognize cats vs. dogs, the output layer might have two nodes: one for “cat” and one for “dog.” The node with the higher value is the network’s answer.
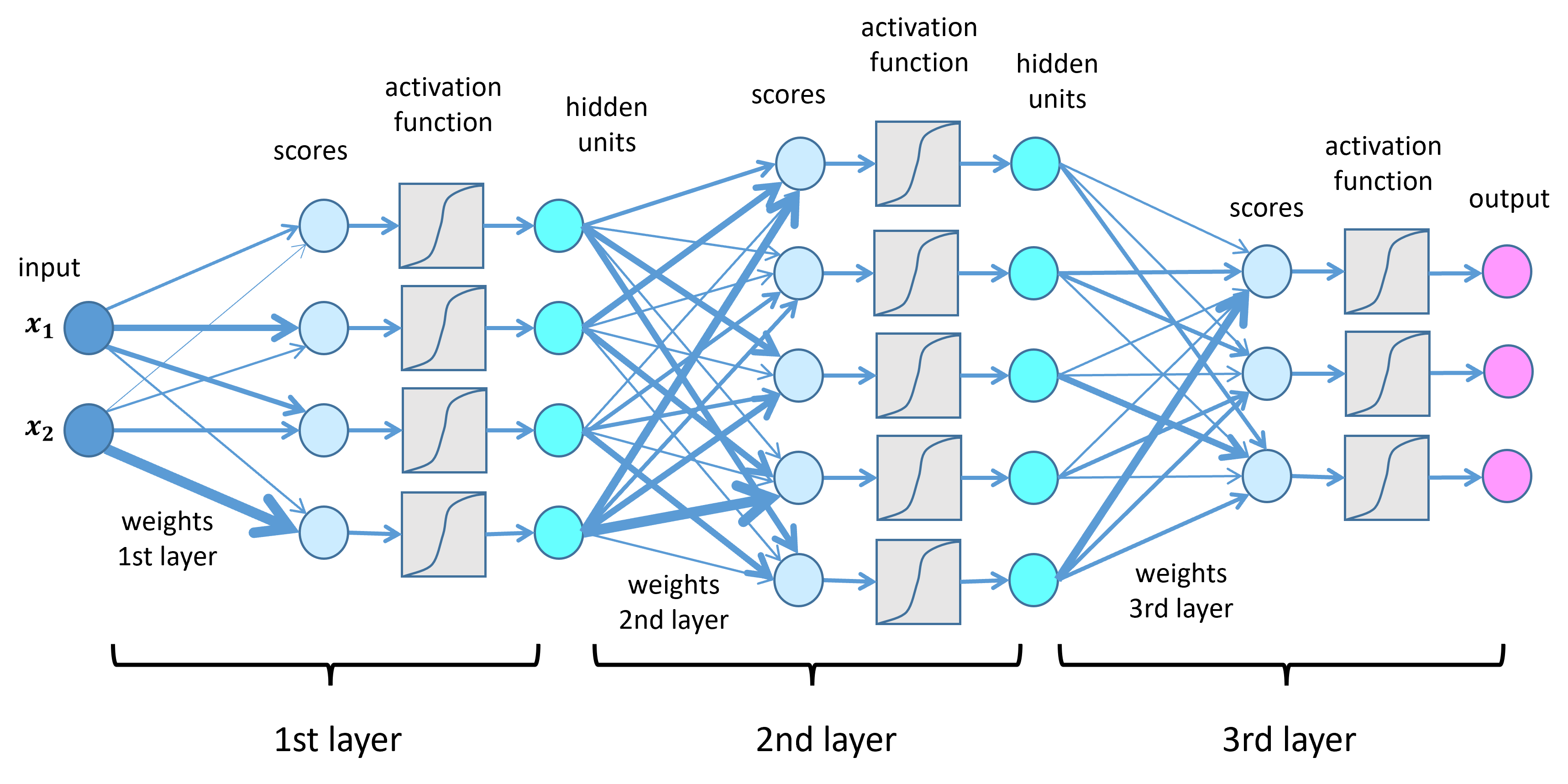
3. How Neural Networks Learn (Training)
A network isn’t smart to begin with. It “learns” by figuring out the perfect weights for all its connections. This learning process is called training.
The training process generally follows these steps:
Initialize Weights: The network starts by assigning random, small numbers to all the weights. At this point, it’s just making wild guesses.
Forward Propagation: You feed the network a piece of data from your training set (e.g., an image of a handwritten ‘5’). The data flows forward—from the input layer, through the hidden layers, to the output layer. The network makes a prediction (e.g., it might guess ‘8’).
Calculate Error: The network compares its prediction (‘8’) to the correct answer (‘5’). The difference between the prediction and the truth is the error (also called “loss”). The goal is to get this error as small as possible.
Backpropagation: This is the most important step. The network works backward from the error, “propagating” it back through the layers. It calculates how much each individual weight contributed to the total error. (In simple terms: “You! This connection… you are 15% responsible for the mistake!”).
Update Weights: Now that the network knows which weights were responsible for the error, it adjusts them all slightly. Connections that led to the wrong answer are made weaker, and connections that might lead to the right answer are made stronger.
Repeat: The network repeats steps 2-5 thousands or millions of times, each time with a new piece of data. With every cycle, the weights get a little bit better, and the network’s predictions become more and more accurate.

4. A Practical Example: Handwritten Digit Recognition
A classic project for learning neural networks is recognizing handwritten digits from the MNIST dataset.
Input: The input is a 28x28 pixel image of a handwritten digit (e.g., a ‘7’). The input layer would have 784 nodes (28 * 28 = 784), one for each pixel.
Training: You “show” the network thousands of these images, each one labeled with the correct answer (e.g., “this image is a 4,” “this one is a 9”).
Process: The network uses the training process (forward propagation, backpropagation, etc.) to learn which patterns of pixels (inputs) are associated with which digits (outputs). It learns that a loop at the top with a line below is often a ‘9’, and a single vertical line is usually a ‘1’.
Output: The output layer has 10 nodes, one for each digit (0-9). When you show the trained network a new image it has never seen, the node corresponding to the correct digit will (hopefully) have the highest activation.
Python Tools: In Python, this is most commonly built using libraries like TensorFlow or PyTorch.
tldr;
neural network is basically connected node with mathematical functions. there are 5 main concepts of a neural network:
- inputs
- weights
- processing
- activation
there are mainly 3 layer of a neural network:
- input layer
- hidden layer
- output layer
and we figure out the weight for a input for a output by training it . simply, how the network figures out the perfect weights for all these connections. That process is called training.
how neural network learns(training) the training process works on 5 steps.
- initialize weights
- forward propagation
- calculate error
- back propagation
- update weights
- repeat steps 2-5 until the error is minimized
a practical example on neural network(with pythons): recognizing handwritten digits